Облачное s3 хранилище: Облачное объектное хранилище – Amazon S3 – Amazon Web Services
Содержание
Классы хранилища Amazon S3 Glacier | AWS
Классы хранилища Amazon S3 Glacier предназначены специально для архивных данных и обеспечивают максимальную производительность, гибкость при извлечении и минимальную стоимость облачного архивного хранилища. Все классы хранилища S3 Glacier имеют практически неограниченную масштабируемость и надежность на уровне 11 девяток (99,999999999 %). Классы хранилища S3 Glacier предоставляют возможности максимально быстрого доступа к архивным данным и минимальную стоимость облачного архивного хранилища.
Вы можете выбрать любой из трех классов хранилища для архивов, оптимизированных под разные шаблоны доступа и длительность хранения. Для архивных данных, к которым может потребоваться мгновенный доступ (например, для медицинских изображений или геномных исследований) лучше выбрать класс хранилища S3 Glacier Instant Retrieval, который предоставляет для архивов самую низкую стоимость хранения и извлечение за несколько миллисекунд. Для архивных данных, к которым не требуется мгновенный доступ, но может потребоваться ситуативный доступ к огромным наборам данных без дополнительных затрат на их извлечение (например, для резервных копий и при аварийном восстановлении), лучше выбрать класс хранилища S3 Glacier Flexible Retrieval (ранее S3 Glacier), который поддерживает извлечение за несколько минут для небольших объемов и за 5–12 часов для пакетов. Чтобы получить минимальную стоимость длительного хранения архивных копий (например, для обеспечения соответствия требованиям или архивов цифровых СМИ) лучше выбрать класс хранилища S3 Glacier Deep Archive, который предоставляет минимальную стоимость облачного архивного хранилища и возможность извлечения данных не позднее двенадцати часов.
Чтобы получить минимальную стоимость длительного хранения архивных копий (например, для обеспечения соответствия требованиям или архивов цифровых СМИ) лучше выбрать класс хранилища S3 Glacier Deep Archive, который предоставляет минимальную стоимость облачного архивного хранилища и возможность извлечения данных не позднее двенадцати часов.
Introduction to the Amazon S3 Glacier Storage Classes (1:30)
Учебное пособие по началу работы с классами хранилищ S3 Glacier
Преимущества
Извлечение данных всего за несколько миллисекунд
Классы хранилища Amazon S3 Glacier предоставляют возможность извлечения за периоды от нескольких миллисекунд до нескольких часов в зависимости от требований к производительности. Класс хранилища S3 Glacier Instant Retrieval может предоставлять данные за несколько миллисекунд, что удобно для архивов с необходимостью мгновенного доступа, например для медицинских изображений и для ресурсов новостных СМИ. S3 Glacier Flexible Retrieval поддерживает несколько вариантов скорости извлечения: ускоренное извлечение выполняется обычно за 1–5 минут, стандартное извлечение требует 3–5 часов, а бесплатное пакетное извлечение для данных особо большого размера – обычно 5–12 часов. Класс хранилища Amazon S3 Glacier Deep Archive предлагает два варианта извлечения данных с периодом от 12 до 48 часов.
S3 Glacier Flexible Retrieval поддерживает несколько вариантов скорости извлечения: ускоренное извлечение выполняется обычно за 1–5 минут, стандартное извлечение требует 3–5 часов, а бесплатное пакетное извлечение для данных особо большого размера – обычно 5–12 часов. Класс хранилища Amazon S3 Glacier Deep Archive предлагает два варианта извлечения данных с периодом от 12 до 48 часов.
Подробнее о вариантах извлечения данных Amazon S3 Glacier »
Подробнее о вариантах извлечения данных Amazon S3 Glacier Deep Archive »
Непревзойденная надежность и масштабируемость
Классы хранилища Amazon S3 Glacier работают на основе крупнейшей в мире глобальной облачной инфраструктуры и обеспечивают практически неограниченную масштабируемость и надежность на уровне 11 девяток (99,999999999 %). Данные хранятся в нескольких экземплярах, распределенных по нескольким зонам доступности в разных физических расположениях в пределах региона AWS.
Подробнее о глобальной облачной инфраструктуре AWS »
Самые широкие возможности для обеспечения безопасности и соответствия требованиям
Классы хранилища S3 Glacier обеспечивают сложную интеграцию с сервисом AWS CloudTrail для ведения журналов, мониторинга и сохранения информации о вызовах API хранилища в целях аудита, а также поддерживают три разные формы шифрования. Эти классы хранилища также поддерживают стандарты безопасности и сертификаты соответствия требованиям, включая SEC Rule 17a-4, PCI-DSS, HIPAA/HITECH, FedRAMP, EU GDPR и FISMA. Amazon S3 Object Lock обеспечивает возможность WORM в хранилищах, помогая соответствовать требованиям практически каждого регулирующего органа в мире.
Эти классы хранилища также поддерживают стандарты безопасности и сертификаты соответствия требованиям, включая SEC Rule 17a-4, PCI-DSS, HIPAA/HITECH, FedRAMP, EU GDPR и FISMA. Amazon S3 Object Lock обеспечивает возможность WORM в хранилищах, помогая соответствовать требованиям практически каждого регулирующего органа в мире.
Подробнее о безопасности AWS »
Подробнее о соответствии AWS нормативным требованиям »
Самые низкие расходы
Все классы хранилища S3 Glacier создавались как самые экономичные классы хранилищ для разных шаблонов использования и позволяют архивировать большие объемы данных по очень низкой цене. Это позволяет сохранять все нужные данные в таких примерах использования, как озера данных, аналитика, интернет вещей (IoT), машинное обучение, обеспечение соответствия требованиям и архивирование мультимедийных ресурсов. Никаких минимальных взносов и авансовых платежей: оплате подлежат только используемые ресурсы.
Подробные сведения о ценах на Amazon S3 »
Широкая поддержка со стороны партнеров, разработчиков и сервисов AWS
Помимо интеграции с большинством сервисов AWS существует сообщество сервисов объектного хранилища Amazon S3, в которое входят десятки тысяч консалтинговых компаний, системных интеграторов и независимых поставщиков программного обеспечения. Новые партнеры присоединяются к этому сообществу каждый месяц. Участники партнерской сети AWS адаптировали свои сервисы и программное обеспечение, чтобы использовать классы хранилища Amazon S3 в решениях для резервного копирования и восстановления, архивирования и аварийного восстановления. Ни у одного другого провайдера облачных сервисов нет такого количества партнеров, предлагающих решения, которые заранее интегрированы с сервисом.
Новые партнеры присоединяются к этому сообществу каждый месяц. Участники партнерской сети AWS адаптировали свои сервисы и программное обеспечение, чтобы использовать классы хранилища Amazon S3 в решениях для резервного копирования и восстановления, архивирования и аварийного восстановления. Ни у одного другого провайдера облачных сервисов нет такого количества партнеров, предлагающих решения, которые заранее интегрированы с сервисом.
Подробнее о партнерах AWS по хранилищам »
Согласованность на протяжении всего жизненного цикла данных
Все классы хранилища S3 Glacier доступны во всех регионах AWS, используют стандартные API S3 и поддерживают все возможности S3, включая S3 Storage Lens для просмотра данных о потреблении и метрик активности, шифрование на стороне сервера для данных объектов, S3 Object Lock для предотвращения случайного удаления и AWS PrivateLink для доступа к S3 через частные точки или VPC. Также вы можете использовать S3 Lifecyle для передачи данных в любой из классов хранилища S3, чтобы снизить затраты на хранение данных, доступ к которым осуществляется редко.
Как это работает. Классы хранилища S3 Glacier
Обзор
Классы хранилища Amazon S3 Glacier предназначены специально для архивных данных и обеспечивают максимальную производительность, гибкость при извлечении и минимальную стоимость облачного архивного хранилища. Теперь вы можете выбрать любой из трех классов хранилища для архивов, оптимизированных под разные шаблоны доступа и длительность хранения.
Класс хранилища Amazon S3 Glacier Instant Retrieval
S3 Glacier Instant Retrieval предоставляет самое экономичное хранилище, снижая затраты на 68 % (по сравнению с S3 Standard – Infrequent Access) для данных, которые нужно хранить долго и получать примерно раз в квартал, но с задержкой в несколько миллисекунд.
 Этот класс рассчитан на данные, к которым редко обращаются, но которые должны быть мгновенно доступны для стандартных примеров использования с высокими требованиями к эффективности, таких как обмен файлами, размещение фотографий, медицинских изображений и историй болезни, ресурсов новостных СМИ, спутниковых и аэрофотоснимков. Хранилище S3 Glacier Instant Retrieval обеспечивает высокую надежность, высокую пропускную способность и низкие задержки на уровне хранилища S3 Standard – IA по более низкой цене за хранение гигабайта данных и по немного более высокой цене за извлечение гигабайта данных. S3 Glacier Instant Retrieval обеспечивает надежность хранения данных на уровне 11 девяток (99,999999999 %) и доступность на уровне 99,9 % за год благодаря использованию избыточного размещения в нескольких физически удаленных зонах доступности AWS.
Этот класс рассчитан на данные, к которым редко обращаются, но которые должны быть мгновенно доступны для стандартных примеров использования с высокими требованиями к эффективности, таких как обмен файлами, размещение фотографий, медицинских изображений и историй болезни, ресурсов новостных СМИ, спутниковых и аэрофотоснимков. Хранилище S3 Glacier Instant Retrieval обеспечивает высокую надежность, высокую пропускную способность и низкие задержки на уровне хранилища S3 Standard – IA по более низкой цене за хранение гигабайта данных и по немного более высокой цене за извлечение гигабайта данных. S3 Glacier Instant Retrieval обеспечивает надежность хранения данных на уровне 11 девяток (99,999999999 %) и доступность на уровне 99,9 % за год благодаря использованию избыточного размещения в нескольких физически удаленных зонах доступности AWS.Класс хранилища Amazon S3 Glacier Flexible Retrieval
S3 Glacier Flexible Retrieval предоставляет экономичное хранилище, снижая затраты на 10 % (по сравнению с S3 Glacier Instant Retrieval) для архивных данных, которые нужно получать пару раз в год в асинхронном режиме.
Класс хранилища S3 Glacier Flexible Retrieval (ранее назывался S3 Glacier) идеально подходит для архивных данных, к которым не требуется мгновенный доступ, но может потребоваться ситуативный доступ к огромным наборам данных без дополнительных затрат на их извлечение (например, для резервных копий и при аварийном восстановлении). S3 Glacier Flexible Retrieval предоставляет наиболее гибкий баланс между стоимостью и скоростью доступа, позволяя получать данные за несколько минут или за несколько часов в пакетном режиме. Это идеальное решение для резервного копирования, аварийного восстановления, хранения данных вне предприятия или для других данных, которые нужно иногда получать с задержкой в несколько минут и на хранение которых нет смысла тратить много средств. S3 Glacier Flexible Retrieval обеспечивает надежность хранения данных на уровне 11 девяток (99,999999999 %) и доступность на уровне 99,99 % за год благодаря использованию избыточного размещения в нескольких физически удаленных зонах доступности AWS.Класс хранилища «Глубокий архив Amazon S3 Glacier»
Глубокий архив S3 Glacier предоставляет самый дешевый вариант хранилища, позволяя снизить затраты на 75 % (по сравнению с гибким извлечением данных S3 Glacier) для архивных данных длительного хранения, доступ к которым требуется не чаще раза в год и может выполняться в асинхронном режиме. Глубокий архив S3 Glacier стоит 0,00099 USD за гигабайт в месяц (или 1 USD за терабайт в месяц), то есть представляет собой самое дешевое хранилище в облаке. Сервис обходится существенно дешевле, чем хранение и обслуживание данных в локальном хранилище на лентах или в удаленных архивах. S3 Glacier Deep Archive является экономичной и удобной в обслуживании альтернативой магнитным лентам. Он создан для клиентов, которые хранят наборы данных 7–10 лет или дольше, для выполнения потребностей клиента и нормативных требований.
Это особенно актуально для таких отраслей, как СМИ и развлечения, здравоохранение, финансовый и государственный сектор. S3 Glacier Deep Archive обеспечивает надежность хранения данных на уровне 11 девяток (99,999999999 %) и доступность на уровне 99,99 % за год благодаря использованию избыточного размещения в нескольких физически удаленных зонах доступности AWS.
 Этот класс рассчитан на данные, к которым редко обращаются, но которые должны быть мгновенно доступны для стандартных примеров использования с высокими требованиями к эффективности, таких как обмен файлами, размещение фотографий, медицинских изображений и историй болезни, ресурсов новостных СМИ, спутниковых и аэрофотоснимков. Хранилище S3 Glacier Instant Retrieval обеспечивает высокую надежность, высокую пропускную способность и низкие задержки на уровне хранилища S3 Standard – IA по более низкой цене за хранение гигабайта данных и по немного более высокой цене за извлечение гигабайта данных. S3 Glacier Instant Retrieval обеспечивает надежность хранения данных на уровне 11 девяток (99,999999999 %) и доступность на уровне 99,9 % за год благодаря использованию избыточного размещения в нескольких физически удаленных зонах доступности AWS.
Этот класс рассчитан на данные, к которым редко обращаются, но которые должны быть мгновенно доступны для стандартных примеров использования с высокими требованиями к эффективности, таких как обмен файлами, размещение фотографий, медицинских изображений и историй болезни, ресурсов новостных СМИ, спутниковых и аэрофотоснимков. Хранилище S3 Glacier Instant Retrieval обеспечивает высокую надежность, высокую пропускную способность и низкие задержки на уровне хранилища S3 Standard – IA по более низкой цене за хранение гигабайта данных и по немного более высокой цене за извлечение гигабайта данных. S3 Glacier Instant Retrieval обеспечивает надежность хранения данных на уровне 11 девяток (99,999999999 %) и доступность на уровне 99,9 % за год благодаря использованию избыточного размещения в нескольких физически удаленных зонах доступности AWS. Класс хранилища S3 Glacier Flexible Retrieval (ранее назывался S3 Glacier) идеально подходит для архивных данных, к которым не требуется мгновенный доступ, но может потребоваться ситуативный доступ к огромным наборам данных без дополнительных затрат на их извлечение (например, для резервных копий и при аварийном восстановлении). S3 Glacier Flexible Retrieval предоставляет наиболее гибкий баланс между стоимостью и скоростью доступа, позволяя получать данные за несколько минут или за несколько часов в пакетном режиме. Это идеальное решение для резервного копирования, аварийного восстановления, хранения данных вне предприятия или для других данных, которые нужно иногда получать с задержкой в несколько минут и на хранение которых нет смысла тратить много средств. S3 Glacier Flexible Retrieval обеспечивает надежность хранения данных на уровне 11 девяток (99,999999999 %) и доступность на уровне 99,99 % за год благодаря использованию избыточного размещения в нескольких физически удаленных зонах доступности AWS.
Класс хранилища S3 Glacier Flexible Retrieval (ранее назывался S3 Glacier) идеально подходит для архивных данных, к которым не требуется мгновенный доступ, но может потребоваться ситуативный доступ к огромным наборам данных без дополнительных затрат на их извлечение (например, для резервных копий и при аварийном восстановлении). S3 Glacier Flexible Retrieval предоставляет наиболее гибкий баланс между стоимостью и скоростью доступа, позволяя получать данные за несколько минут или за несколько часов в пакетном режиме. Это идеальное решение для резервного копирования, аварийного восстановления, хранения данных вне предприятия или для других данных, которые нужно иногда получать с задержкой в несколько минут и на хранение которых нет смысла тратить много средств. S3 Glacier Flexible Retrieval обеспечивает надежность хранения данных на уровне 11 девяток (99,999999999 %) и доступность на уровне 99,99 % за год благодаря использованию избыточного размещения в нескольких физически удаленных зонах доступности AWS.
 Это особенно актуально для таких отраслей, как СМИ и развлечения, здравоохранение, финансовый и государственный сектор. S3 Glacier Deep Archive обеспечивает надежность хранения данных на уровне 11 девяток (99,999999999 %) и доступность на уровне 99,99 % за год благодаря использованию избыточного размещения в нескольких физически удаленных зонах доступности AWS.
Это особенно актуально для таких отраслей, как СМИ и развлечения, здравоохранение, финансовый и государственный сектор. S3 Glacier Deep Archive обеспечивает надежность хранения данных на уровне 11 девяток (99,999999999 %) и доступность на уровне 99,99 % за год благодаря использованию избыточного размещения в нескольких физически удаленных зонах доступности AWS.Примеры использования
Рабочие процессы с использованием мультимедийных ресурсов
Для ресурсов индустрии СМИ и развлечений (например, видеозаписей или выпусков новостей) требуется надежное хранилище, поддерживающее расширение до нескольких петабайтов. Основная часть таких данных должна быть мгновенно доступна для важных новостных событий, отрисовки видео или подготовки другого контента. Класс хранилища Amazon S3 Glacier Instant Retrieval позволяет архивировать мультимедийное содержимое, не тратя на это лишних средств, но сохраняя возможность доступа к нему за несколько миллисекунд, когда это потребуется. Для дополнительной экономии при хранении таких архивов, к которым не нужен мгновенный доступ, рекомендуем выбрать S3 Glacier или S3 Glacier Deep Archive.
Для дополнительной экономии при хранении таких архивов, к которым не нужен мгновенный доступ, рекомендуем выбрать S3 Glacier или S3 Glacier Deep Archive.
Архивирование данных в сфере здравоохранения
В соответствии с нормативными требованиями медицинские учреждения обязаны хранить данные медицинских карт (например, ЛИС, системы архивации и передачи изображений и электронные медицинские карты). Объем таких данных исчисляется петабайтами. Классы хранилища Amazon S3 Glacier и S3 Glacier Deep Archive позволяют надежно архивировать данные медицинских карт пациентов по очень низкой цене. Класс хранилища Amazon S3 Glacier Instant Retrieval идеально подходит для хранения медицинских изображений и геномных исследований, к которым может потребоваться мгновенный доступ.
Архивирование для соблюдения бизнес-политик, нормативных требований и соответствия требованиям
Многие предприятия в таких сферах, как финансовые сервисы и здравоохранение, для соответствия нормативным требованиям обязаны в течение продолжительного времени хранить архивы. Сервис Amazon S3 Object Lock позволяет установить параметры соответствия политикам, удовлетворяющие SEC Rule 17a‑4(f) или другим требованиям. Политики компаний также могут требовать длительного (несколько лет или неограниченно долго) хранения таких данных, как финансовая и налоговая документация, сведения о сотрудниках и архивы электронных писем. Такое содержимое долгосрочного хранения можно разместить в классах хранилища S3 Glacier.
Сервис Amazon S3 Object Lock позволяет установить параметры соответствия политикам, удовлетворяющие SEC Rule 17a‑4(f) или другим требованиям. Политики компаний также могут требовать длительного (несколько лет или неограниченно долго) хранения таких данных, как финансовая и налоговая документация, сведения о сотрудниках и архивы электронных писем. Такое содержимое долгосрочного хранения можно разместить в классах хранилища S3 Glacier.
Хранение научных данных
Исследовательские организации создают, анализируют и архивируют огромные объемы данных, особенно в отраслях геномных исследований и машинного обучения. Класс хранилища Amazon S3 Glacier Instant Retrieval позволит избежать любых сложностей с подготовкой оборудования, управления помещениями и планирования емкости, сохраняя минимальную стоимость хранения и возможность доступа за несколько миллисекунд.
Сохранение цифровых материалов
Библиотеки и правительственные учреждения регулярно сталкиваются с проблемами обеспечения целостности данных в процессе цифровой архивации. В отличие от традиционных систем, в которых могут применяться сложные механизмы проверки данных и ручная коррекция, Amazon S3 систематически осуществляет проверку целостности данных и обладает свойством автоматического самовосстановления. С помощью S3 Lifecyle вы можете перенести данные в более экономичные классы хранилища, чтобы оптимизировать затраты.
В отличие от традиционных систем, в которых могут применяться сложные механизмы проверки данных и ручная коррекция, Amazon S3 систематически осуществляет проверку целостности данных и обладает свойством автоматического самовосстановления. С помощью S3 Lifecyle вы можете перенести данные в более экономичные классы хранилища, чтобы оптимизировать затраты.
Долгосрочное хранение резервных копий
Планы резервного копирования у многих предприятий предусматривают хранение огромных объемов данных в течение нескольких лет в дорогих локальных системах хранения. Классы хранилища S3 Glacier обеспечат хранение архивных данных по минимальной цене, сохраняя возможность доступа к ним по мере необходимости.
Замена магнитных лент
Локальные и внешние ленточные библиотеки снижают затраты на хранение, однако требуют значительных предварительных вложений и особого обслуживания. Классы хранилища Amazon S3 Glacier не требуют никаких предварительных вложений и полностью устраняют затраты на обслуживание оборудования, при этом обеспечивая более быстрый доступ, чем в локальном хранилище магнитных лент.![]()
Примеры использования
Rock & Roll Hall of Fame сохраняет историю рок-музыки и развивается на AWS.
Ознакомиться с примером использования »
Qube Cinema сокращает затраты на 80% благодаря архивации в Amazon S3 Glacier.
Ознакомиться с примером использования »
Reuters создает легкодоступные масштабные новостные архивы в Amazon S3 Glacier.
BandLab сокращает затраты и улучшает доступность с помощью Amazon S3 Glacier.
Ознакомиться с примером использования »
Joyn делает эксклюзивный контент для аудитории с Amazon S3 Intelligent-Tiering и Amazon S3 Glacier.
Блоги об Amazon S3 Glacier
В настоящее время публикаций по Amazon S3 нет. Чтобы просмотреть все публикации о хранилищах, посетите блог AWS.
Начать работу с классами хранилища Amazon S3 Glacier
Зарегистрировать бесплатный аккаунт
Получите мгновенный доступ к уровню бесплатного пользования AWS.
Регистрация
Учитесь на практических учебных пособиях
Начните хранить архивные наборы данных в классах хранилища Amazon S3 Glacier.
Посмотреть учебное пособие
Начните создавать системы с использованием классов хранилища Amazon S3 Glacier
Для начала работы изучите Руководство пользователя Amazon S3.
Читать документацию
Подробнее о возможностях Amazon S3
Перейти на страницу с описанием возможностей
Начать работу с Amazon S3 Glacier
Посмотреть учебное пособие
Есть вопросы?
Связаться с нами
Вход в Консоль
Подробнее об AWS
- Что такое AWS?
- Что такое облачные вычисления?
- Инклюзивность, многообразие и равенство AWS
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Безопасность облака AWS
- Новые возможности
- Блоги
- Пресс‑релизы
Ресурсы для работы с AWS
- Начало работы
- Обучение и сертификация
- Портфолио решений AWS
- Центр архитектурных решений
- Вопросы и ответы по продуктам и техническим темам
- Отчеты аналитиков
- Партнерская сеть AWS
Разработчики на AWS
- Центр разработчика
- Пакеты SDK и инструментарий
- . NET на AWS
- Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
 NET на AWS
NET на AWSПоддержка
- Связаться с нами
- Работа в AWS
- Обратиться в службу поддержки
- Центр знаний
- AWS re:Post
- Обзор AWS Support
- Юридическая информация
Amazon.com – работодатель равных возможностей. Мы предоставляем равные права
представителям меньшинств, женщинам, лицам с ограниченными возможностями, ветеранам боевых действий и представителям любых гендерных групп любой сексуальной ориентации независимо от их возраста.
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari.
Подробнее »
Возможность Amazon S3 Batch Operations – AWS
Управляйте десятками или даже миллиардами объектов при любом масштабе с помощью S3 Batch Operations
S3 Batch Operations – это возможность управления данными Amazon S3, с помощью которой можно администрировать миллиарды объектов при любом масштабе несколькими щелчками мыши в консоли управления Amazon S3 или один запрос API. С помощью этой возможности можно вносить изменения в метаданные и свойства объектов и выполнять другие операции по управлению хранилищем, такие как копирование или репликация объектов из одной корзины в другую, замена набора тегов объекта, изменение ограничений доступа и восстановление архивных объектов из S3 Glacier (вместо того, чтобы тратить месяцы на разработку собственных приложений для решения подобных задач).
С помощью этой возможности можно вносить изменения в метаданные и свойства объектов и выполнять другие операции по управлению хранилищем, такие как копирование или репликация объектов из одной корзины в другую, замена набора тегов объекта, изменение ограничений доступа и восстановление архивных объектов из S3 Glacier (вместо того, чтобы тратить месяцы на разработку собственных приложений для решения подобных задач).
Знакомство с Amazon S3 Batch Operations (2:03)
S3 Batch Operations
S3 Batch Operations – это управляемое решение для выполнения операций с хранилищем, таких как копирование объектов и сопровождение их тегами при любом масштабе; оно подходит как для разовых задач, так и для повторяющихся пакетных рабочих нагрузок. Благодаря S3 Batch Operations операцию с миллиардами объектов и петабайтами данных можно выполнить за один запрос. Для работы в S3 Batch Operations нужно создать задание. Задание состоит из перечня объектов, действия, которое необходимо совершить, и набора параметров, задаваемых пользователем для операции этого типа. В S3 Batch Operations можно создать и выполнить множество заданий одновременно или же с помощью приоритетов настроить порядок заданий, чтобы самые важные операции выполнялись в первую очередь. Возможность S3 Batch Operations также управляет повторными попытками, отслеживает ход выполнения, уведомляет о завершении заданий, составляет отчеты и фиксирует события, соответствующие каждому совершенному изменению и выполненному заданию, в AWS CloudTrail.
В S3 Batch Operations можно создать и выполнить множество заданий одновременно или же с помощью приоритетов настроить порядок заданий, чтобы самые важные операции выполнялись в первую очередь. Возможность S3 Batch Operations также управляет повторными попытками, отслеживает ход выполнения, уведомляет о завершении заданий, составляет отчеты и фиксирует события, соответствующие каждому совершенному изменению и выполненному заданию, в AWS CloudTrail.
S3 Batch Operations станет отличным дополнением для любой существующей архитектуры, управляемой событиями. Когда в корзине появляются новые объекты, с помощью событий S3 и функций Lambda можно без труда преобразовывать типы файлов, создавать миниатюры, считывать данные и выполнять другие операции. Например, с помощью событий S3 и функций Lambda пользователи могут создавать версии исходных фотографий меньшего размера и разрешения, когда изображения впервые загружаются в S3. Для таких существующих управляемых событиями рабочих процессов решение S3 Batch Operations предоставляет простой способ выполнения этих же операций и с существующими объектами.
S3 Batch Operations: принцип работы
Для работы в S3 Batch Operations нужно создать задание. Задание состоит из перечня объектов, действия, которое необходимо совершить, и набора параметров, задаваемых пользователем для операции этого типа. В S3 Batch Operations можно создать и выполнить множество заданий одновременно или же с помощью приоритетов настроить порядок заданий, чтобы самые важные операции выполнялись в первую очередь. Возможность S3 Batch Operations также управляет повторными попытками, отслеживает ход выполнения, уведомляет о завершении заданий, составляет отчеты и фиксирует события, соответствующие каждому совершенному изменению и выполненному заданию, в AWS CloudTrail.
Учебные пособия по S3 Batch Operations
Создание задания
Создайте задание Batch Operations
Управление заданиями и их отслеживание
Управляйте заданием Batch Operations и отслеживайте его выполнение
Настройка разрешений
Настраивайте разрешения
Клиенты
Компания Teespring была основана в 2011 году.![]() Она предоставляет платформу для создания и продажи оригинальных продуктов по требованию через Интернет. Продажа каждого оригинального изделия затрагивает множество ресурсов на платформе Teespring. Для хранения петабайтов данных эта компания выбрала Amazon S3.
Она предоставляет платформу для создания и продажи оригинальных продуктов по требованию через Интернет. Продажа каждого оригинального изделия затрагивает множество ресурсов на платформе Teespring. Для хранения петабайтов данных эта компания выбрала Amazon S3.
«Благодаря возможности Amazon S3 Batch Operations нам удалось привести наше хранилище в оптимальное состояние. Мы воспользовались хранилищем Amazon S3 Glacier. На основе метаданных нашего хранилища мы создали пакеты объектов, которые можно было перемещать в Amazon S3 Glacier. Хранилище Amazon S3 Glacier позволило нам сократить затраты на хранение данных более чем на 80 %. Мы постоянно ищем возможности автоматизировать управление хранилищем, и благодаря S3 Batch Operations управление миллионами объектов становится делом нескольких минут».
Джеймс Брейди, вице‑президент по разработке, Teespring
Банк Capital One был основан на стыке сферы финансовых сервисов и современных технологий. Это один из самых узнаваемых брендов США.
Это один из самых узнаваемых брендов США.
Capital One использовал Amazon S3 Batch Operations для копирования данных из одного региона AWS в другой с целью создания резервных копий этих данных и приведения объема данных в двух рассматриваемых регионах к единому стандарту.
«С помощью Amazon S3 Batch Operations мы создали задание для копирования миллионов объектов за несколько часов. Обычно на это уходило несколько месяцев. В наше задание Amazon S3 Batch Operations мы включили содержимое отчета об инвентаризации Amazon S3, в котором были перечислены объекты из нашей корзины. Возможности Amazon S3 помогли нам скопировать данные, информировали о ходе выполнения задания и сформировали аудиторское заключение, когда задание было завершено. Такое решение избавила нашу команду от нескольких недель ручного труда и превратила крупномасштабный перенос данных в рядовую операцию».
Франц Зэмен, вице‑президент по разработке программного обеспечения, Capital One
ePlus, опытный партнер‑консультант AWS, помогает своим клиентам оптимизировать ИТ‑среды и использует такие решения, как S3 Batch Operations, чтобы сэкономить их время и деньги.
«Возможность S3 Batch Operations просто невероятна. Она не только сэкономила время наших клиентов и упростила трудоемкий процесс, требовавший согласовать множество операций S3, спланировать задания и перевести информацию в простой вид для отображения на панели управления. Эта возможность также избавила нас от нервотрепки в нескольких случаях, в которых, по моему мнению, справиться за короткий промежуток времени было нереально. Но благодаря S3 Batch Operations все стало возможным.
К примеру, решение S3 Batch Operations позволило быстро скопировать более 2 миллионов объектов из одного региона в другой в рамках одного аккаунта, и наши метаданные не пострадали. Работа шла безукоризненно: решение выполнило схожие задания в разных аккаунтах и, что самое важное, составило отчет о завершении, в котором операции с 400 миллионами объектов были автоматически поделены на удачные и неудачные.
 Все операции, которые не удалось выполнить, были помещены в один файл, что упростило дальнейшую работу с ними.
Все операции, которые не удалось выполнить, были помещены в один файл, что упростило дальнейшую работу с ними.Дэвид Лин, старший архитектор решений, обладатель сертификации AWS Certified Professional, ePlus
Публикации в блогах, посвященные S3 Batch Operations
Блог AWS News
Amazon S3 Batch Operations
С помощью решения Amazon S3 Batch Operations можно без труда обработать сотни, миллионы и миллиарды объектов S3. Решение позволяет копировать объекты в другую корзину, сопровождать их тегами или создавать списки контроля доступа (ACL), выполнять восстановление из резервной копии в S3 Glacier или вызывать к каждому объекту функцию AWS Lambda.
Читать блог »
Блог AWS Storage
Encrypting objects with S3 Batch Operations
В этой публикации показано, как создать список объектов, включить в него только незашифрованные объекты с помощью фильтров, настроить разрешения и выполнить задание S3 Batch Operations для шифрования объектов. Шифрование существующих объектов – лишь одна из многих задач, которую можно решить с помощью решения S3 Batch Operations, предназначенного для управления объектами Amazon S3.
Шифрование существующих объектов – лишь одна из многих задач, которую можно решить с помощью решения S3 Batch Operations, предназначенного для управления объектами Amazon S3.
Читать блог »
Блог AWS Storage
Transcoding video files with S3 Batch Operations
В этой публикации описывается, как использовать S3 Batch Operations, чтобы запустить задание по перекодированию видео с помощью AWS Lambda – на основе видео, хранящегося в S3, или видео, которое нужно восстановить из резервной копии в Amazon S3 Glacier.
Читать блог »
Просмотрите запись вебинара Tech Talk, посвященного S3 Batch Operations
Узнайте, как начать работу, и познакомьтесь с рекомендациями.
Подробнее
Зарегистрировать бесплатный аккаунт
Получите мгновенный доступ к уровню бесплатного пользования AWS.
Регистрация
Начало разработки в консоли
Начните разработку с помощью Amazon S3 в Консоли управления AWS.
Вход
Вход в Консоль
Подробнее об AWS
- Что такое AWS?
- Что такое облачные вычисления?
- Инклюзивность, многообразие и равенство AWS
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Безопасность облака AWS
- Новые возможности
- Блоги
- Пресс‑релизы
Ресурсы для работы с AWS
- Начало работы
- Обучение и сертификация
- Портфолио решений AWS
- Центр архитектурных решений
- Вопросы и ответы по продуктам и техническим темам
- Отчеты аналитиков
- Партнерская сеть AWS
Разработчики на AWS
- Центр разработчика
- Пакеты SDK и инструментарий
- .NET на AWS
- Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
Поддержка
- Связаться с нами
- Работа в AWS
- Обратиться в службу поддержки
- Центр знаний
- AWS re:Post
- Обзор AWS Support
- Юридическая информация
Amazon. com – работодатель равных возможностей. Мы предоставляем равные права
com – работодатель равных возможностей. Мы предоставляем равные права
представителям меньшинств, женщинам, лицам с ограниченными возможностями, ветеранам боевых действий и представителям любых гендерных групп любой сексуальной ориентации независимо от их возраста.
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari.
Подробнее »
классов объектных хранилищ — Amazon S3
Amazon S3 предлагает ряд классов хранилищ, которые вы можете выбрать в зависимости от требований к доступу к данным, отказоустойчивости и стоимости ваших рабочих нагрузок. Классы хранения S3 созданы специально для обеспечения хранения с наименьшими затратами для различных моделей доступа. Классы хранения S3 идеально подходят практически для любого случая использования, в том числе с высокими требованиями к производительности, местонахождению данных, неизвестным или меняющимся шаблонам доступа или архивному хранилищу.
Классы хранения S3 включают S3 Intelligent-Tiering для автоматического снижения затрат на данные с неизвестными или изменяющимися схемами доступа, S3 Standard для часто используемых данных, S3 Standard-Infrequent Access (S3 Standard-IA) и S3 One Zone-Infrequent Access (S3 One Zone-IA) для редко используемых данных, S3 Glacier Instant Retrieval для архивных данных, к которым требуется немедленный доступ, S3 Glacier Flexible Retrieval (ранее S3 Glacier) для редко используемых долгосрочных данных, не требующих немедленного доступа, и Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive) для долговременного архивирования и сохранения в цифровом виде с извлечением в течение нескольких часов при самом низком уровне затрат на хранение в облаке. Если у вас есть требования к местонахождению данных, которые не может удовлетворить существующий регион AWS, вы можете использовать класс хранилища S3 Outposts для локального хранения данных S3. Amazon S3 также предлагает возможности для управления вашими данными на протяжении всего их жизненного цикла. После установки политики жизненного цикла S3 ваши данные будут автоматически перенесены в другой класс хранилища без каких-либо изменений в вашем приложении.
Amazon S3 также предлагает возможности для управления вашими данными на протяжении всего их жизненного цикла. После установки политики жизненного цикла S3 ваши данные будут автоматически перенесены в другой класс хранилища без каких-либо изменений в вашем приложении.
Просмотреть инфографику с обзором классов хранилища Amazon S3 »
Общего назначения
Amazon S3 Standard (S3 Standard)
S3 Standard предлагает объектное хранилище с высокой надежностью, доступностью и производительностью для часто используемых данных. Поскольку он обеспечивает низкую задержку и высокую пропускную способность, S3 Standard подходит для самых разных вариантов использования, включая облачные приложения, динамические веб-сайты, распространение контента, мобильные и игровые приложения, а также аналитику больших данных. Классы хранилища S3 можно настроить на уровне объектов, и один сегмент может содержать объекты, хранящиеся в S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA и S3 One Zone-IA. Вы также можете использовать политики жизненного цикла S3 для автоматического перемещения объектов между классами хранения без каких-либо изменений в приложении.
Вы также можете использовать политики жизненного цикла S3 для автоматического перемещения объектов между классами хранения без каких-либо изменений в приложении.
Основные характеристики:
- Низкая задержка и высокая пропускная способность
- Разработан для долговечности 99,999999999% объектов в нескольких зонах доступности
- Устойчивость к событиям, влияющим на всю зону доступности
- Обеспечивает доступность на уровне 99,99 % в течение заданного года
- Доступность поддерживается соглашением об уровне обслуживания Amazon S3
- Поддерживает SSL для передачи данных и шифрование данных в состоянии покоя
- Управление жизненным циклом S3 для автоматической миграции объектов в другие классы хранилища S3
Неизвестный или изменяющийся доступ
Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering)
Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering) — первое облачное хранилище, которое автоматически снижает затраты на хранение на уровне отдельных объектов за счет автоматического перемещения данных на наиболее экономичный уровень доступа в зависимости от частоты доступа без снижения производительности, платы за извлечение или операционных издержек. S3 Intelligent-Tiering обеспечивает миллисекундную задержку и высокую пропускную способность для часто, нечасто и редко используемых данных на уровнях частого, редкого и архивного мгновенного доступа. Вы можете использовать S3 Intelligent-Tiering в качестве класса хранилища по умолчанию практически для любой рабочей нагрузки, особенно для озер данных, анализа данных, новых приложений и пользовательского контента.
S3 Intelligent-Tiering обеспечивает миллисекундную задержку и высокую пропускную способность для часто, нечасто и редко используемых данных на уровнях частого, редкого и архивного мгновенного доступа. Вы можете использовать S3 Intelligent-Tiering в качестве класса хранилища по умолчанию практически для любой рабочей нагрузки, особенно для озер данных, анализа данных, новых приложений и пользовательского контента.
За небольшую ежемесячную плату за мониторинг и автоматизацию объектов S3 Intelligent-Tiering отслеживает шаблоны доступа и автоматически перемещает объекты, к которым не было доступа, на более дешевые уровни доступа. S3 Intelligent-Tiering автоматически сохраняет объекты на трех уровнях доступа: один уровень, оптимизированный для частого доступа, уровень с более низкой стоимостью на 40 %, оптимизированный для нечастого доступа, и уровень с более низкой стоимостью на 68 %, оптимизированный для редко используемых данных. S3 Intelligent-Tiering отслеживает шаблоны доступа и перемещает объекты, к которым не обращались в течение 30 дней подряд, на уровень нечастого доступа и через 9 дней. 0 дней без доступа к уровню мгновенного доступа к архиву. Для данных, которые не требуют немедленного извлечения, вы можете настроить S3 Intelligent-Tiering для отслеживания и автоматического перемещения объектов, к которым нет доступа в течение 180 или более дней, на уровень Deep Archive Access, чтобы сэкономить до 95 % затрат на хранение.
0 дней без доступа к уровню мгновенного доступа к архиву. Для данных, которые не требуют немедленного извлечения, вы можете настроить S3 Intelligent-Tiering для отслеживания и автоматического перемещения объектов, к которым нет доступа в течение 180 или более дней, на уровень Deep Archive Access, чтобы сэкономить до 95 % затрат на хранение.
В S3 Intelligent-Tiering плата за извлечение не взимается. Если доступ к объекту на уровне «Нечасто» или «Мгновенный доступ к архиву» осуществляется позже, он автоматически перемещается обратно на уровень «Частый доступ». Если объект, который вы извлекаете, хранится на дополнительных уровнях глубокого архива, прежде чем вы сможете извлечь объект, вы должны сначала восстановить копию с помощью RestoreObject. Сведения о восстановлении заархивированных объектов см. в разделе Восстановление заархивированных объектов. При перемещении объектов между уровнями доступа в классе хранения S3 Intelligent-Tiering дополнительная плата за многоуровневое хранение не взимается.
Основные характеристики:
- Уровни частого, нечастого и архивного мгновенного доступа имеют такую же производительность с низкой задержкой и высокой пропускной способностью, что и S3 Standard
- Уровень нечастого доступа экономит до 40 % затрат на хранение
- Уровень мгновенного доступа к архиву экономит до 68 % затрат на хранение
- Возможности асинхронного архивирования по желанию для объектов, к которым редко обращаются
- Разработано для обеспечения долговечности 99,999999999 % объектов в нескольких зонах доступности и доступности 99,9 % в течение заданного года
- Доступность поддерживается соглашением об уровне обслуживания Amazon S3
- Небольшая ежемесячная плата за мониторинг и автоматическое распределение по уровням
- Без операционных накладных расходов, без платы за жизненный цикл, без платы за извлечение и без минимальной продолжительности хранения
- Объекты размером менее 128 КБ могут храниться в S3 Intelligent-Tiering, но с них всегда будет взиматься плата по тарифам уровня частого доступа, а плата за мониторинг и автоматизацию не взимается.
9Уровень доступа к глубокому архиву 0037 имеет такую же производительность, что и Glacier Deep Archive, и обеспечивает экономию до 95 % для редко используемых объектов

Нечастый доступ
Amazon S3 Standard-Infrequent Access (S3 Standard-IA)
S3 Standard-IA предназначен для данных, доступ к которым осуществляется реже, но при необходимости требуется быстрый доступ. S3 Standard-IA предлагает высокую надежность, высокую пропускную способность и низкую задержку S3 Standard, а также низкую стоимость хранения за ГБ и плату за извлечение за ГБ. Такое сочетание низкой стоимости и высокой производительности делает S3 Standard-IA идеальным решением для долговременного хранения, резервного копирования и хранения данных для файлов аварийного восстановления. Классы хранилища S3 можно настроить на уровне объектов, и один сегмент может содержать объекты, хранящиеся в S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA и S3 One Zone-IA. Вы также можете использовать политики жизненного цикла S3 для автоматического перемещения объектов между классами хранения без каких-либо изменений в приложении.
Основные характеристики:
- Такая же низкая задержка и высокая пропускная способность, как у S3 Standard
- Разработан для обеспечения долговечности 99,999999999% объектов в нескольких зонах доступности
- Устойчивость к событиям, влияющим на всю зону доступности
- Данные устойчивы в случае разрушения одной зоны доступности
- Обеспечивает доступность на уровне 99,9 % в течение заданного года
- Доступность поддерживается соглашением об уровне обслуживания Amazon S3
- Поддерживает SSL для передачи данных и шифрование данных в состоянии покоя
- Управление жизненным циклом S3 для автоматической миграции объектов в другие классы хранения S3
Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA)
S3 One Zone-IA предназначен для данных, доступ к которым осуществляется реже, но при необходимости требуется быстрый доступ. В отличие от других классов хранения S3, которые хранят данные как минимум в трех зонах доступности (AZ), S3 One Zone-IA хранит данные в одной зоне доступности и стоит на 20 % меньше, чем S3 Standard-IA. S3 One Zone-IA идеально подходит для клиентов, которым нужен недорогой вариант для редко используемых данных, но не требуется доступность и отказоустойчивость S3 Standard или S3 Standard-IA. Это хороший выбор для хранения вторичных резервных копий локальных данных или легко воссоздаваемых данных. Вы также можете использовать его в качестве экономичного хранилища для данных, которые реплицируются из другого региона AWS с помощью межрегиональной репликации S3.
В отличие от других классов хранения S3, которые хранят данные как минимум в трех зонах доступности (AZ), S3 One Zone-IA хранит данные в одной зоне доступности и стоит на 20 % меньше, чем S3 Standard-IA. S3 One Zone-IA идеально подходит для клиентов, которым нужен недорогой вариант для редко используемых данных, но не требуется доступность и отказоустойчивость S3 Standard или S3 Standard-IA. Это хороший выбор для хранения вторичных резервных копий локальных данных или легко воссоздаваемых данных. Вы также можете использовать его в качестве экономичного хранилища для данных, которые реплицируются из другого региона AWS с помощью межрегиональной репликации S3.
S3 One Zone-IA предлагает такую же высокую надежность†, высокую пропускную способность и малую задержку, что и S3 Standard, с низкой ценой хранения за ГБ и платой за извлечение за ГБ. Классы хранилища S3 можно настроить на уровне объектов, и в одном сегменте могут храниться объекты, хранящиеся в S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA и S3 One Zone-IA. Вы также можете использовать политики жизненного цикла S3 для автоматического перемещения объектов между классами хранения без каких-либо изменений в приложении.
Вы также можете использовать политики жизненного цикла S3 для автоматического перемещения объектов между классами хранения без каких-либо изменений в приложении.
Основные характеристики:
- Такая же низкая задержка и высокая пропускная способность, как у S3 Standard
- Разработан для долговечности 99,999999999% объектов в одной зоне доступности†
- Рассчитан на доступность на уровне 99,5 % в течение заданного года
- Доступность поддерживается соглашением об уровне обслуживания Amazon S3
- Поддерживает SSL для передачи данных и шифрование данных в состоянии покоя
- Управление жизненным циклом S3 для автоматической миграции объектов в другие классы хранения S3
† Поскольку S3 One Zone-IA хранит данные в одной зоне доступности AWS, данные, хранящиеся в этом классе хранения, будут потеряны в случае разрушения зоны доступности.
Архив
Хранилище Amazon S3 Glacier класса специально создано для архивирования данных и предназначено для обеспечения максимальной производительности, максимальной гибкости извлечения и минимальной стоимости архивного хранилища в облаке. Вы можете выбрать один из трех классов архивных хранилищ, оптимизированных для различных моделей доступа и длительности хранения. Для архивных данных, требующих немедленного доступа, таких как медицинские изображения, новостные ресурсы или данные геномики, выберите класс хранилища S3 Glacier Instant Retrieval — класс хранения архивов, который обеспечивает хранение с наименьшими затратами и поиск за миллисекунды. Для архивных данных, которые не требуют немедленного доступа, но нуждаются в гибкости для бесплатного извлечения больших наборов данных, например, для резервного копирования или аварийного восстановления, выберите S3 Glacier Flexible Retrieval (ранее S3 Glacier) с извлечением в течение нескольких минут или бесплатным массовым извлечением. извлечения через 5—12 часов. Чтобы еще больше сэкономить на долгоживущем архивном хранилище, таком как архивы соответствия и сохранение цифровых носителей, выберите S3 Glacier Deep Archive — самое недорогое хранилище в облаке с извлечением данных от 12 до 48 часов.
Вы можете выбрать один из трех классов архивных хранилищ, оптимизированных для различных моделей доступа и длительности хранения. Для архивных данных, требующих немедленного доступа, таких как медицинские изображения, новостные ресурсы или данные геномики, выберите класс хранилища S3 Glacier Instant Retrieval — класс хранения архивов, который обеспечивает хранение с наименьшими затратами и поиск за миллисекунды. Для архивных данных, которые не требуют немедленного доступа, но нуждаются в гибкости для бесплатного извлечения больших наборов данных, например, для резервного копирования или аварийного восстановления, выберите S3 Glacier Flexible Retrieval (ранее S3 Glacier) с извлечением в течение нескольких минут или бесплатным массовым извлечением. извлечения через 5—12 часов. Чтобы еще больше сэкономить на долгоживущем архивном хранилище, таком как архивы соответствия и сохранение цифровых носителей, выберите S3 Glacier Deep Archive — самое недорогое хранилище в облаке с извлечением данных от 12 до 48 часов.
Amazon S3 Glacier Instant Retrieval
Amazon S3 Glacier Instant Retrieval — это класс хранилища архивов, обеспечивающий самое дешевое хранилище для долгоживущих данных, к которым редко обращаются и которые требуют извлечения за миллисекунды. С S3 Glacier Instant Retrieval вы можете сэкономить до 68 % на стоимости хранения по сравнению с классом хранилища S3 Standard-Infrequent Access (S3 Standard-IA), когда доступ к вашим данным осуществляется один раз в квартал. S3 Glacier Instant Retrieval обеспечивает самый быстрый доступ к архивному хранилищу с той же пропускной способностью и доступом в миллисекундах, что и классы хранения S3 Standard и S3 Standard-IA. S3 Glacier Instant Retrieval идеально подходит для архивных данных, к которым требуется немедленный доступ, таких как медицинские изображения, новостные ресурсы или архивы контента, созданного пользователями. Вы можете загружать объекты непосредственно в S3 Glacier Instant Retrieval или использовать политики жизненного цикла S3 для передачи данных из классов хранения S3. Для получения дополнительной информации посетите Страница мгновенного поиска Amazon S3 Glacier »
Для получения дополнительной информации посетите Страница мгновенного поиска Amazon S3 Glacier »
Основные характеристики:
- Извлечение данных в миллисекундах с той же производительностью, что и у S3 Standard
- Разработан для долговечности 99,999999999% объектов в нескольких зонах доступности
- Данные устойчивы в случае разрушения одной всей зоны доступности
- Разработано для доступности данных на уровне 99,9 % в заданном году
- Минимальный размер объекта 128 КБ
- Доступность поддерживается соглашением об уровне обслуживания Amazon S3
- S3 PUT API для прямой загрузки в S3 Glacier Instant Retrieval и управление жизненным циклом S3 для автоматической миграции объектов
Amazon S3 Glacier Flexible Retrieval (ранее S3 Glacier)
S3 Glacier Flexible Retrieval обеспечивает недорогое хранилище до 10 % дешевле (по сравнению с S3 Glacier Instant Retrieval) для архивных данных, доступ к которым осуществляется 1–2 раза в год. и извлекается асинхронно. Для архивных данных, которые не требуют немедленного доступа, но нуждаются в гибкости для бесплатного извлечения больших наборов данных, например, в случаях резервного копирования или аварийного восстановления, S3 Glacier Flexible Retrieval (ранее S3 Glacier) является идеальным классом хранилища. S3 Glacier Flexible Retrieval предлагает самые гибкие варианты поиска, которые уравновешивают стоимость и время доступа в диапазоне от минут до часов, а также бесплатные массовые запросы. Это идеальное решение для резервного копирования, аварийного восстановления, удаленного хранения данных, а также в тех случаях, когда некоторые данные иногда необходимо получить за считанные минуты, и вы не хотите беспокоиться о затратах. S3 Glacier Flexible Retrieval рассчитан на 99,999999999 % (11 девяток) надежности данных и 99,99 % доступности за счет избыточного хранения данных в нескольких физически разделенных зонах доступности AWS в течение заданного года. Для получения дополнительной информации посетите страницу классов хранилища Amazon S3 Glacier »
и извлекается асинхронно. Для архивных данных, которые не требуют немедленного доступа, но нуждаются в гибкости для бесплатного извлечения больших наборов данных, например, в случаях резервного копирования или аварийного восстановления, S3 Glacier Flexible Retrieval (ранее S3 Glacier) является идеальным классом хранилища. S3 Glacier Flexible Retrieval предлагает самые гибкие варианты поиска, которые уравновешивают стоимость и время доступа в диапазоне от минут до часов, а также бесплатные массовые запросы. Это идеальное решение для резервного копирования, аварийного восстановления, удаленного хранения данных, а также в тех случаях, когда некоторые данные иногда необходимо получить за считанные минуты, и вы не хотите беспокоиться о затратах. S3 Glacier Flexible Retrieval рассчитан на 99,999999999 % (11 девяток) надежности данных и 99,99 % доступности за счет избыточного хранения данных в нескольких физически разделенных зонах доступности AWS в течение заданного года. Для получения дополнительной информации посетите страницу классов хранилища Amazon S3 Glacier »
Основные характеристики:
- Разработано для надежности 99,999999999 % объектов в нескольких зонах доступности
- Данные устойчивы в случае полного уничтожения одной зоны доступности
- Поддерживает SSL для передачи данных и шифрование данных в состоянии покоя
- Идеально подходит для случаев резервного копирования и аварийного восстановления, когда большие наборы данных иногда необходимо извлечь за считанные минуты, не заботясь о затратах
- Настраиваемое время извлечения, от минут до часов, с бесплатным массовым извлечением
- S3 PUT API для прямой загрузки в S3 Glacier Flexible Retrieval и управление жизненным циклом S3 для автоматической миграции объектов
Amazon S3 Glacier Deep Archive
S3 Glacier Deep Archive — это самый дешевый класс хранилищ Amazon S3, поддерживающий долгосрочное хранение и цифровое сохранение данных, к которым можно обращаться один или два раза в год. Он предназначен для клиентов, особенно в строго регулируемых отраслях, таких как финансовые услуги, здравоохранение и государственный сектор, которые хранят наборы данных в течение 7–10 лет или дольше для соблюдения нормативных требований. S3 Glacier Deep Archive также можно использовать для резервного копирования и аварийного восстановления. Это экономичная и простая в управлении альтернатива системам на магнитных лентах, независимо от того, являются ли они локальными библиотеками или удаленными службами. S3 Glacier Deep Archive дополняет Amazon S3 Glacier, который идеально подходит для архивов, в которых данные извлекаются регулярно, а некоторые данные могут понадобиться в течение нескольких минут. Все объекты, хранящиеся в S3 Glacier Deep Archive, реплицируются и хранятся как минимум в трех географически распределенных зонах доступности, защищенных 9Прочность 9,999999999%, возможность восстановления в течение 12 часов. Для получения дополнительной информации посетите страницу классов хранилища Amazon S3 Glacier »
Он предназначен для клиентов, особенно в строго регулируемых отраслях, таких как финансовые услуги, здравоохранение и государственный сектор, которые хранят наборы данных в течение 7–10 лет или дольше для соблюдения нормативных требований. S3 Glacier Deep Archive также можно использовать для резервного копирования и аварийного восстановления. Это экономичная и простая в управлении альтернатива системам на магнитных лентах, независимо от того, являются ли они локальными библиотеками или удаленными службами. S3 Glacier Deep Archive дополняет Amazon S3 Glacier, который идеально подходит для архивов, в которых данные извлекаются регулярно, а некоторые данные могут понадобиться в течение нескольких минут. Все объекты, хранящиеся в S3 Glacier Deep Archive, реплицируются и хранятся как минимум в трех географически распределенных зонах доступности, защищенных 9Прочность 9,999999999%, возможность восстановления в течение 12 часов. Для получения дополнительной информации посетите страницу классов хранилища Amazon S3 Glacier »
Основные характеристики:
- Разработано для надежности 99,999999999% объектов в нескольких зонах доступности
- Самый дешевый класс хранилищ, предназначенный для длительного хранения данных в течение 7–10 лет
- Идеальная альтернатива библиотекам на магнитных лентах
- Время поиска в течение 12 часов
- S3 PUT API для прямой загрузки в S3 Glacier Deep Archive и управления жизненным циклом S3 для автоматической миграции объектов
S3 на Outposts
S3 Outposts
Amazon S3 на Outposts обеспечивает хранение объектов в вашей локальной среде AWS Outposts. Используя API-интерфейсы и функции S3, доступные сегодня в регионах AWS, S3 на Outposts упрощает хранение и извлечение данных на вашем Outpost, а также защиту данных, управление доступом, маркировку и создание отчетов по ним. S3 на Outposts предоставляет единый класс хранилища Amazon S3 под названием «OUTPOSTS», который использует API-интерфейсы S3 и предназначен для надежного и избыточного хранения данных на нескольких устройствах и серверах в ваших Outposts. Класс хранилища S3 Outposts идеально подходит для рабочих нагрузок с требованиями к локальному размещению данных, а также для удовлетворения высоких требований к производительности за счет хранения данных рядом с локальными приложениями.
Используя API-интерфейсы и функции S3, доступные сегодня в регионах AWS, S3 на Outposts упрощает хранение и извлечение данных на вашем Outpost, а также защиту данных, управление доступом, маркировку и создание отчетов по ним. S3 на Outposts предоставляет единый класс хранилища Amazon S3 под названием «OUTPOSTS», который использует API-интерфейсы S3 и предназначен для надежного и избыточного хранения данных на нескольких устройствах и серверах в ваших Outposts. Класс хранилища S3 Outposts идеально подходит для рабочих нагрузок с требованиями к локальному размещению данных, а также для удовлетворения высоких требований к производительности за счет хранения данных рядом с локальными приложениями.
Основные характеристики:
- Совместимость с объектами S3 и управление сегментами с помощью S3 SDK
- Предназначен для надежного и избыточного хранения данных на ваших аванпостах
- Шифрование с использованием SSE-S3 и SSE-C
- Аутентификация и авторизация с использованием IAM и точек доступа S3
- Передача данных в регионы AWS с помощью AWS DataSync
- Действия по истечении срока службы S3
Производительность в классах хранения S3
† Поскольку S3 One Zone-IA хранит данные в одной зоне доступности AWS, данные, хранящиеся в этом классе хранения, будут потеряны в случае разрушения зоны доступности.
* S3 Intelligent-Tiering взимает небольшую плату за мониторинг и автоматизацию, а минимальный допустимый размер объекта составляет 128 КБ для автоматического распределения по уровням. Меньшие объекты могут храниться, но всегда будут оплачиваться по тарифам уровня частого доступа, а плата за мониторинг и автоматизацию не взимается. Дополнительные сведения см. в разделе Цены на Amazon S3.
** Стандартное извлечение на уровне доступа к архиву и уровне доступа к глубокому архиву бесплатно. Используя консоль S3, вы можете оплатить ускоренное извлечение, если вам нужен более быстрый доступ к вашим данным с уровней доступа к архиву.
*** S3 Intelligent-Tiering Задержка первого байта для уровня частого и нечастого доступа составляет время доступа в миллисекундах, а задержка первого байта для уровней доступа к архиву и глубокому доступу к архиву составляет минуты или часы.
Возможности Amazon S3 — Amazon Web Services
В Amazon S3 есть различные функции, которые можно использовать для организации данных и управления ими в соответствии с конкретными вариантами использования, экономичностью, обеспечением безопасности и соблюдением нормативных требований. Данные хранятся в виде объектов в ресурсах, называемых «сегментами», и один объект может иметь размер до 5 терабайт. Функции S3 включают в себя возможность добавлять теги метаданных к объектам, перемещать и хранить данные в классах хранения S3, настраивать и применять элементы управления доступом к данным, защищать данные от неавторизованных пользователей, запускать анализ больших данных, отслеживать данные на уровне объектов и сегментов, а также просматривать использование хранилища и тенденции активности в вашей организации. Доступ к объектам можно получить через точки доступа S3 или напрямую через имя хоста корзины.
Данные хранятся в виде объектов в ресурсах, называемых «сегментами», и один объект может иметь размер до 5 терабайт. Функции S3 включают в себя возможность добавлять теги метаданных к объектам, перемещать и хранить данные в классах хранения S3, настраивать и применять элементы управления доступом к данным, защищать данные от неавторизованных пользователей, запускать анализ больших данных, отслеживать данные на уровне объектов и сегментов, а также просматривать использование хранилища и тенденции активности в вашей организации. Доступ к объектам можно получить через точки доступа S3 или напрямую через имя хоста корзины.
Управление хранилищем и мониторинг
Плоская, неиерархическая структура Amazon S3 и различные функции управления помогают клиентам всех размеров и отраслей организовывать свои данные таким образом, чтобы это было ценно для их бизнеса и команд. Все объекты хранятся в корзинах S3 и могут быть организованы с помощью общих имен, называемых префиксами. Вы также можете добавить до 10 пар ключ-значение, называемых тегами объекта S3 , к каждому объекту, которые можно создавать, обновлять и удалять на протяжении всего жизненного цикла объекта. Чтобы отслеживать объекты и их соответствующие теги, сегменты и префиксы, вы можете использовать Отчет S3 Inventory , в котором перечислены ваши сохраненные объекты в корзине S3 или с определенным префиксом, а также их соответствующие метаданные и состояние шифрования. S3 Inventory можно настроить для создания отчетов ежедневно или еженедельно.
Чтобы отслеживать объекты и их соответствующие теги, сегменты и префиксы, вы можете использовать Отчет S3 Inventory , в котором перечислены ваши сохраненные объекты в корзине S3 или с определенным префиксом, а также их соответствующие метаданные и состояние шифрования. S3 Inventory можно настроить для создания отчетов ежедневно или еженедельно.
Управление хранилищем
Благодаря именам корзин S3, префиксам, тегам объектов и инвентаризации S3 у вас есть ряд способов категоризировать данные и создавать отчеты, а затем можно настроить другие функции S3 для выполнения действий. Независимо от того, храните ли вы тысячи объектов или миллиард, 9Пакетные операции 0005 S3 упрощают управление данными в Amazon S3 в любом масштабе. С помощью S3 Batch Operations вы можете копировать объекты между сегментами, заменять наборы тегов объектов, изменять элементы управления доступом и восстанавливать заархивированные объекты из классов хранения S3 Glacier Flexible Retrieval и S3 Glacier Deep Archive с помощью одного запроса S3 API или нескольких щелчков мышью в Консоль S3. Вы также можете использовать S3 Batch Operations для запуска функций AWS Lambda на ваших объектах для выполнения пользовательской бизнес-логики, такой как обработка данных или перекодирование файлов изображений. Чтобы начать работу, укажите список целевых объектов, используя отчет S3 Inventory или предоставив настраиваемый список, а затем выберите нужную операцию из предварительно заполненного меню. Когда запрос на пакетную операцию S3 будет выполнен, вы получите уведомление и отчет о выполнении всех внесенных изменений. Узнайте больше о пакетных операциях S3, просмотрев обучающие видео.
Вы также можете использовать S3 Batch Operations для запуска функций AWS Lambda на ваших объектах для выполнения пользовательской бизнес-логики, такой как обработка данных или перекодирование файлов изображений. Чтобы начать работу, укажите список целевых объектов, используя отчет S3 Inventory или предоставив настраиваемый список, а затем выберите нужную операцию из предварительно заполненного меню. Когда запрос на пакетную операцию S3 будет выполнен, вы получите уведомление и отчет о выполнении всех внесенных изменений. Узнайте больше о пакетных операциях S3, просмотрев обучающие видео.
Amazon S3 также поддерживает функции, помогающие поддерживать контроль версий данных, предотвращать случайное удаление и реплицировать данные в тот же или другой регион AWS. С помощью S3 Versioning вы можете легко сохранять, извлекать и восстанавливать каждую версию объекта, хранящуюся в Amazon S3, что позволяет вам восстанавливаться после непреднамеренных действий пользователя и сбоев приложений. Чтобы предотвратить случайное удаление, включите многофакторную аутентификацию (MFA) Удалить в корзине S3. Если вы попытаетесь удалить объект, хранящийся в корзине с поддержкой удаления MFA, для этого потребуются две формы аутентификации: учетные данные вашей учетной записи AWS и объединение действительного серийного номера, пробела и шестизначного кода, отображаемого на утвержденном устройство аутентификации, например аппаратный брелок или ключ безопасности Universal 2nd Factor (U2F).
Чтобы предотвратить случайное удаление, включите многофакторную аутентификацию (MFA) Удалить в корзине S3. Если вы попытаетесь удалить объект, хранящийся в корзине с поддержкой удаления MFA, для этого потребуются две формы аутентификации: учетные данные вашей учетной записи AWS и объединение действительного серийного номера, пробела и шестизначного кода, отображаемого на утвержденном устройство аутентификации, например аппаратный брелок или ключ безопасности Universal 2nd Factor (U2F).
С помощью S3 Replication вы можете реплицировать объекты (и их соответствующие метаданные и теги объектов) в одну или несколько целевых корзин в те же или разные регионы AWS для уменьшения задержки, соответствия требованиям, безопасности, аварийного восстановления и других вариантов использования. Вы можете настроить межрегиональную репликацию S3 (CRR) для репликации объектов из исходной корзины S3 в одну или несколько целевых корзин в разных регионах AWS. S3 Same-Region Replication (SRR) реплицирует объекты между корзинами в одном и том же регионе AWS. В то время как живая репликация, такая как CRR и SRR, автоматически реплицирует новые загруженные объекты по мере их записи в вашу корзину, пакетная репликация S3 позволяет вам реплицировать существующие объекты. Вы можете использовать пакетную репликацию S3 для заполнения вновь созданной корзины существующими объектами, повторной попытки объектов, которые ранее не могли реплицироваться, переноса данных между учетными записями или добавления новых корзин в ваше озеро данных. Amazon S3 Replication Time Control (S3 RTC) помогает соблюдать нормативные требования к репликации данных, предоставляя соглашение об уровне обслуживания и информацию о времени репликации.
В то время как живая репликация, такая как CRR и SRR, автоматически реплицирует новые загруженные объекты по мере их записи в вашу корзину, пакетная репликация S3 позволяет вам реплицировать существующие объекты. Вы можете использовать пакетную репликацию S3 для заполнения вновь созданной корзины существующими объектами, повторной попытки объектов, которые ранее не могли реплицироваться, переноса данных между учетными записями или добавления новых корзин в ваше озеро данных. Amazon S3 Replication Time Control (S3 RTC) помогает соблюдать нормативные требования к репликации данных, предоставляя соглашение об уровне обслуживания и информацию о времени репликации.
Мультирегиональные точки доступа Amazon S3 повышают производительность до 60 % при доступе к наборам данных, которые реплицируются в нескольких регионах AWS. На основе AWS Global Accelerator мультирегиональные точки доступа S3 учитывают такие факторы, как перегрузка сети и местоположение запрашивающего приложения, чтобы динамически направлять ваши запросы по сети AWS к копии ваших данных с наименьшей задержкой. Мультирегиональные точки доступа S3 предоставляют единую глобальную конечную точку, которую можно использовать для доступа к реплицированному набору данных, охватывающему несколько сегментов в S3. Это позволяет создавать приложения для нескольких регионов с той же простой архитектурой, которую вы использовали бы в одном регионе, а затем запускать эти приложения в любой точке мира.
Мультирегиональные точки доступа S3 предоставляют единую глобальную конечную точку, которую можно использовать для доступа к реплицированному набору данных, охватывающему несколько сегментов в S3. Это позволяет создавать приложения для нескольких регионов с той же простой архитектурой, которую вы использовали бы в одном регионе, а затем запускать эти приложения в любой точке мира.
Вы также можете применять политики однократной записи-многократного чтения (WORM) с помощью S3 Object Lock . Эта функция управления S3 блокирует удаление версии объекта в течение периода хранения, определенного пользователем, чтобы вы могли применять политики хранения в качестве дополнительного уровня защиты данных или для выполнения обязательств по соблюдению требований. Вы можете перенести рабочие нагрузки из существующих систем WORM в Amazon S3 и настроить блокировку объектов S3 на уровне объекта и корзины, чтобы предотвратить удаление версии объекта до предварительно определенной даты «сохранить до даты» или «даты юридического удержания». Объекты с блокировкой объектов S3 сохраняют защиту WORM, даже если они перемещаются в другие классы хранения с помощью политики жизненного цикла S3. Чтобы отследить, какие объекты имеют блокировку объектов S3, вы можете обратиться к отчету S3 Inventory, который включает статус объектов WORM. S3 Object Lock можно настроить в одном из двух режимов. При развертывании в режиме управления учетные записи AWS с определенными разрешениями IAM могут снимать блокировку объектов S3 с объектов. Если вам требуется более строгая неизменность для соблюдения нормативных требований, вы можете использовать режим соответствия. В режиме соответствия защиту не может снять ни один пользователь, включая учетную запись root.
Объекты с блокировкой объектов S3 сохраняют защиту WORM, даже если они перемещаются в другие классы хранения с помощью политики жизненного цикла S3. Чтобы отследить, какие объекты имеют блокировку объектов S3, вы можете обратиться к отчету S3 Inventory, который включает статус объектов WORM. S3 Object Lock можно настроить в одном из двух режимов. При развертывании в режиме управления учетные записи AWS с определенными разрешениями IAM могут снимать блокировку объектов S3 с объектов. Если вам требуется более строгая неизменность для соблюдения нормативных требований, вы можете использовать режим соответствия. В режиме соответствия защиту не может снять ни один пользователь, включая учетную запись root.
Мониторинг хранилища
В дополнение к этим возможностям управления используйте функции Amazon S3 и другие сервисы AWS для мониторинга и управления ресурсами S3. Применяйте теги к корзинам S3, чтобы распределять затраты по нескольким бизнес-измерениям (таким как центры затрат, имена приложений или владельцы), а затем используйте отчеты о распределении затрат AWS , чтобы просмотреть использование и затраты, объединенные тегами корзины. Вы также можете использовать Amazon CloudWatch для отслеживания работоспособности ваших ресурсов AWS и настройки уведомлений о выставлении счетов для расчетных расходов, которые достигают заданного пользователем порога. Используйте AWS CloudTrail для отслеживания и составления отчетов о действиях на уровне сегментов и объектов, а также настроить уведомления о событиях S3 для запуска рабочих процессов и оповещений или вызова AWS Lambda при внесении определенных изменений в ваши ресурсы S3. Уведомления о событиях S3 автоматически перекодируют медиафайлы по мере их загрузки в S3, обрабатывают файлы данных по мере их появления и синхронизируют объекты с другими хранилищами данных. Кроме того, вы можете проверить целостность данных, передаваемых в Amazon S3 и из него, и получить доступ к информации о контрольной сумме в любое время с помощью API GetObjectAttributes S3 или отчета S3 Inventory. Вы можете выбрать один из четырех поддерживаемых алгоритмов контрольной суммы (SHA-1, SHA-256, CRC32 или CRC32C) для проверки целостности данных в ваших запросах на загрузку и выгрузку в зависимости от потребностей вашего приложения.
Вы также можете использовать Amazon CloudWatch для отслеживания работоспособности ваших ресурсов AWS и настройки уведомлений о выставлении счетов для расчетных расходов, которые достигают заданного пользователем порога. Используйте AWS CloudTrail для отслеживания и составления отчетов о действиях на уровне сегментов и объектов, а также настроить уведомления о событиях S3 для запуска рабочих процессов и оповещений или вызова AWS Lambda при внесении определенных изменений в ваши ресурсы S3. Уведомления о событиях S3 автоматически перекодируют медиафайлы по мере их загрузки в S3, обрабатывают файлы данных по мере их появления и синхронизируют объекты с другими хранилищами данных. Кроме того, вы можете проверить целостность данных, передаваемых в Amazon S3 и из него, и получить доступ к информации о контрольной сумме в любое время с помощью API GetObjectAttributes S3 или отчета S3 Inventory. Вы можете выбрать один из четырех поддерживаемых алгоритмов контрольной суммы (SHA-1, SHA-256, CRC32 или CRC32C) для проверки целостности данных в ваших запросах на загрузку и выгрузку в зависимости от потребностей вашего приложения.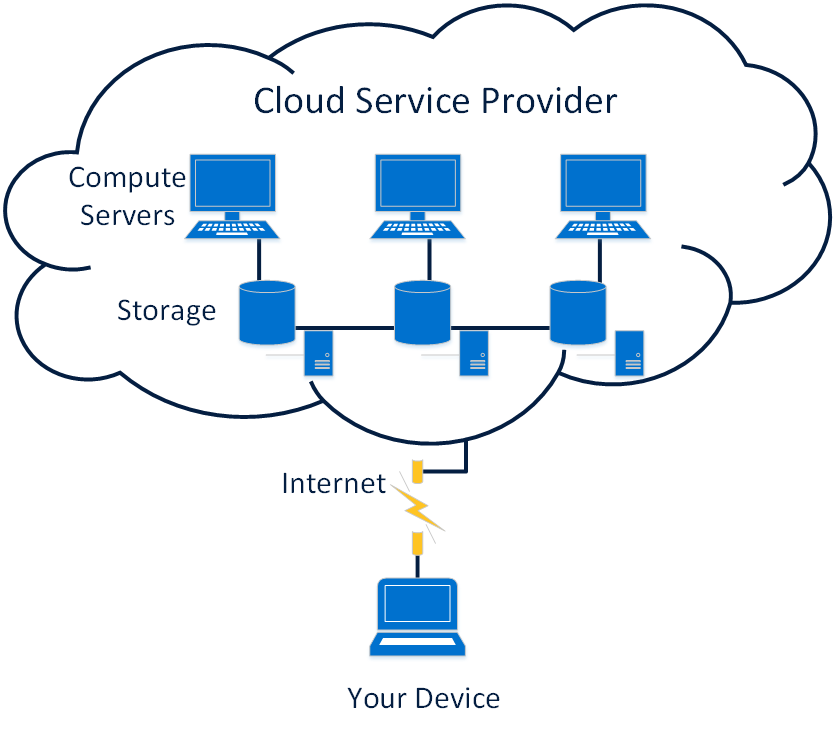
В дополнение к этим возможностям управления вы можете использовать функции S3 и другие сервисы AWS для мониторинга и контроля использования ваших ресурсов S3. Вы можете применить теги к корзинам S3, чтобы распределить затраты по нескольким бизнес-измерениям (таким как центры затрат, имена приложений или владельцы), а затем использовать Отчеты о распределении затрат AWS для просмотра использования и затрат, объединенных тегами корзины. Вы также можете использовать Amazon CloudWatch для отслеживания работоспособности ваших ресурсов AWS и настройки уведомлений о выставлении счетов, которые отправляются вам, когда расчетные расходы достигают заданного пользователем порога. Еще один сервис мониторинга AWS — AWS CloudTrail , который отслеживает и создает отчеты о действиях на уровне корзины и объекта. Вы можете настроить Уведомления о событиях S3 для запуска рабочих процессов, предупреждений и вызова AWS Lambda при внесении определенных изменений в ваши ресурсы S3.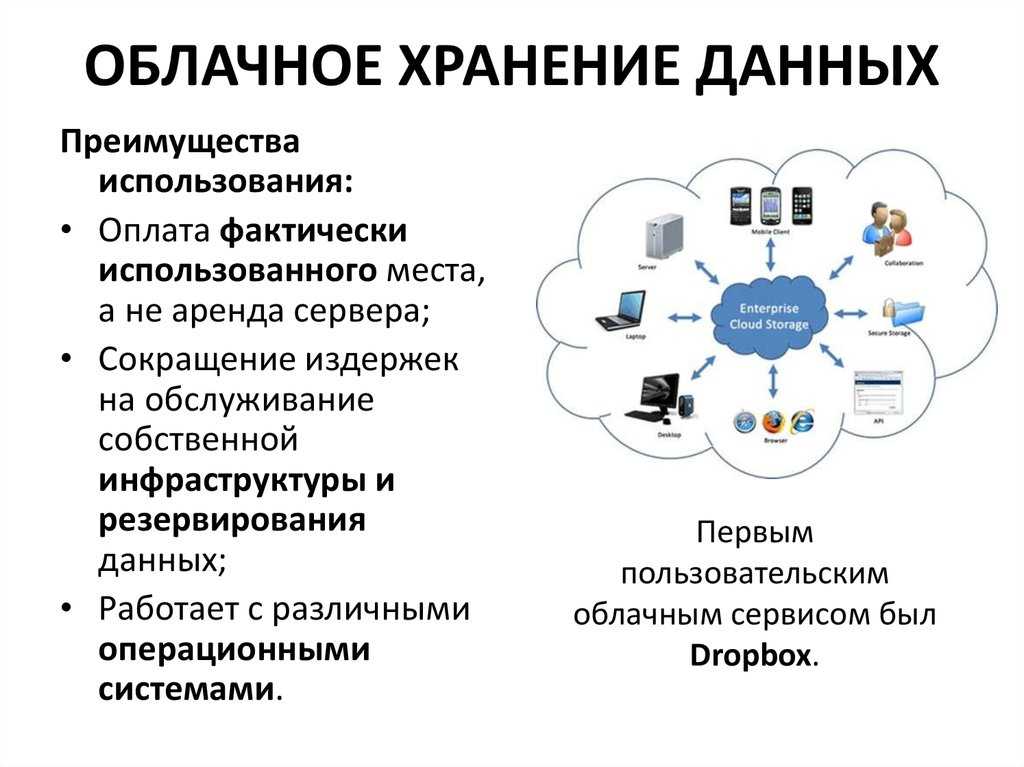 Уведомления о событиях S3 можно использовать для автоматического перекодирования медиафайлов по мере их загрузки в Amazon S3, обработки файлов данных по мере их появления или синхронизации объектов с другими хранилищами данных.
Уведомления о событиях S3 можно использовать для автоматического перекодирования медиафайлов по мере их загрузки в Amazon S3, обработки файлов данных по мере их появления или синхронизации объектов с другими хранилищами данных.
Аналитика систем хранения данных
S3 Storage Lens
S3 Storage Lens обеспечивает представление всей организации об использовании объектного хранилища, тенденциях активности и дает действенные рекомендации по повышению экономической эффективности и применению передовых методов защиты данных. S3 Storage Lens — это первое решение для аналитики облачных хранилищ, обеспечивающее единое представление об использовании и действиях объектного хранилища для сотен или даже тысяч учетных записей в организации с детализацией для получения сведений об учетной записи, сегменте или даже префиксе. уровень. Основываясь на более чем 14-летнем опыте помощи клиентам в оптимизации их хранения, S3 Storage Lens анализирует метрики в масштабах всей организации, чтобы предоставить контекстные рекомендации для поиска способов снижения затрат на хранение и применения передовых методов защиты данных. Чтобы узнать больше, посетите страницу аналитики и информации о хранилище.
Чтобы узнать больше, посетите страницу аналитики и информации о хранилище.
Анализ класса хранилища S3
Анализ класса хранилища Amazon S3 анализирует шаблоны доступа к хранилищу, чтобы помочь вам решить, когда нужно перевести нужные данные в нужный класс хранилища. Эта функция Amazon S3 отслеживает шаблоны доступа к данным, чтобы помочь вам определить, когда следует перевести хранилище, к которому реже обращаются, в хранилище более дешевого класса. Вы можете использовать результаты для улучшения политик жизненного цикла S3. Вы можете настроить анализ класса хранения для анализа всех объектов в корзине. Или вы можете настроить фильтры для группировки объектов для анализа по общему префиксу, по тегам объектов или по префиксу и тегам. Чтобы узнать больше, посетите страницу аналитики и информации о хранилище.
Классы хранения
Amazon S3 позволяет хранить данные в различных классах хранения S3, специально созданных для конкретных случаев использования и шаблонов доступа: S3 Intelligent-Tiering, S3 Standard , S3 Standard-Infrequent Доступ (S3 Standard-IA) , S3 One Zone — нечастый доступ (S3 One Zone-IA) , S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval , S3 Glacier Deep Archive и S3 Outposts .
Каждый класс хранения S3 поддерживает определенный уровень доступа к данным при соответствующих затратах или географическом местоположении.
Для данных с изменяющимися, неизвестными или непредсказуемыми схемами доступа, такими как озера данных, аналитика или новые приложения, используйте S3 Intelligent-Tiering , который автоматически оптимизирует ваши затраты на хранение. S3 Intelligent-Tiering автоматически перемещает ваши данные между тремя уровнями доступа с малой задержкой, оптимизированными для частого, нечастого и редкого доступа. Когда подмножества объектов со временем архивируются, вы можете активировать уровень доступа к архиву, предназначенный для асинхронного доступа.
Для более предсказуемых моделей доступа вы можете хранить критически важные производственные данные в S3 Standard для частого доступа, экономить средства, сохраняя редко используемые данные в S3 Standard-IA или S3 One Zone-IA, а также архивировать данные с минимальными затратами. в классах архивного хранилища — S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval и S3 Glacier Deep Archive. Вы можете использовать S3 Storage Class Analysis для мониторинга шаблонов доступа к объектам, чтобы обнаружить данные, которые следует переместить в более дешевые классы хранения. Затем вы можете использовать эту информацию для настройки S3 Lifecycle политика, выполняющая передачу данных. Политики жизненного цикла S3 также можно использовать для истечения срока действия объектов в конце их жизненного цикла.
в классах архивного хранилища — S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval и S3 Glacier Deep Archive. Вы можете использовать S3 Storage Class Analysis для мониторинга шаблонов доступа к объектам, чтобы обнаружить данные, которые следует переместить в более дешевые классы хранения. Затем вы можете использовать эту информацию для настройки S3 Lifecycle политика, выполняющая передачу данных. Политики жизненного цикла S3 также можно использовать для истечения срока действия объектов в конце их жизненного цикла.
Если у вас есть требования к местонахождению данных, которым не может соответствовать существующий регион AWS, вы можете использовать класс хранения S3 Outposts для локального хранения данных S3 с помощью S3 на Outposts .
Управление доступом и безопасность
Управление доступом
Для защиты ваших данных в Amazon S3 по умолчанию пользователи имеют доступ только к тем ресурсам S3, которые они создают. Вы можете предоставить доступ другим пользователям, используя одну или комбинацию следующих функций управления доступом: AWS Identity and Access Management (IAM) для создания пользователей и управления их соответствующим доступом; Списки контроля доступа (ACL), чтобы сделать отдельные объекты доступными для авторизованных пользователей; Политики корзины для настройки разрешений для всех объектов в пределах одной корзины S3; S3 Access Points для упрощения управления доступом к общим наборам данных путем создания точек доступа с именами и разрешениями, специфичными для каждого приложения или наборов приложений; и Проверка подлинности строки запроса для предоставления ограниченного по времени доступа другим пользователям с временными URL-адресами. Amazon S3 также поддерживает журналы аудита , в которых перечислены запросы, сделанные к вашим ресурсам S3, для полного понимания того, кто и к каким данным обращается.
Вы можете предоставить доступ другим пользователям, используя одну или комбинацию следующих функций управления доступом: AWS Identity and Access Management (IAM) для создания пользователей и управления их соответствующим доступом; Списки контроля доступа (ACL), чтобы сделать отдельные объекты доступными для авторизованных пользователей; Политики корзины для настройки разрешений для всех объектов в пределах одной корзины S3; S3 Access Points для упрощения управления доступом к общим наборам данных путем создания точек доступа с именами и разрешениями, специфичными для каждого приложения или наборов приложений; и Проверка подлинности строки запроса для предоставления ограниченного по времени доступа другим пользователям с временными URL-адресами. Amazon S3 также поддерживает журналы аудита , в которых перечислены запросы, сделанные к вашим ресурсам S3, для полного понимания того, кто и к каким данным обращается.
Безопасность
Amazon S3 предлагает гибкие функции безопасности для блокировки несанкционированного доступа пользователей к вашим данным. Используйте конечные точки VPC для подключения к ресурсам S3 из виртуального частного облака Amazon (Amazon VPC) и из локальной среды. Amazon S3 поддерживает как шифрование на стороне сервера (с тремя вариантами управления ключами), так и шифрование на стороне клиента для загрузки данных. Используйте S3 Inventory для проверки состояния шифрования ваших объектов S3 (дополнительную информацию о S3 Inventory см. в разделе Управление хранилищем).
Используйте конечные точки VPC для подключения к ресурсам S3 из виртуального частного облака Amazon (Amazon VPC) и из локальной среды. Amazon S3 поддерживает как шифрование на стороне сервера (с тремя вариантами управления ключами), так и шифрование на стороне клиента для загрузки данных. Используйте S3 Inventory для проверки состояния шифрования ваших объектов S3 (дополнительную информацию о S3 Inventory см. в разделе Управление хранилищем).
Блокировка общего доступа S3 — это набор элементов управления безопасностью, который гарантирует, что корзины и объекты S3 не будут иметь общего доступа. С помощью нескольких щелчков мыши в консоли управления Amazon S3 вы можете применить настройки S3 Block Public Access ко всем корзинам в вашей учетной записи AWS или к определенным корзинам S3. После применения настроек к учетной записи AWS любые существующие или новые сегменты и объекты, связанные с этой учетной записью, наследуют настройки, запрещающие публичный доступ.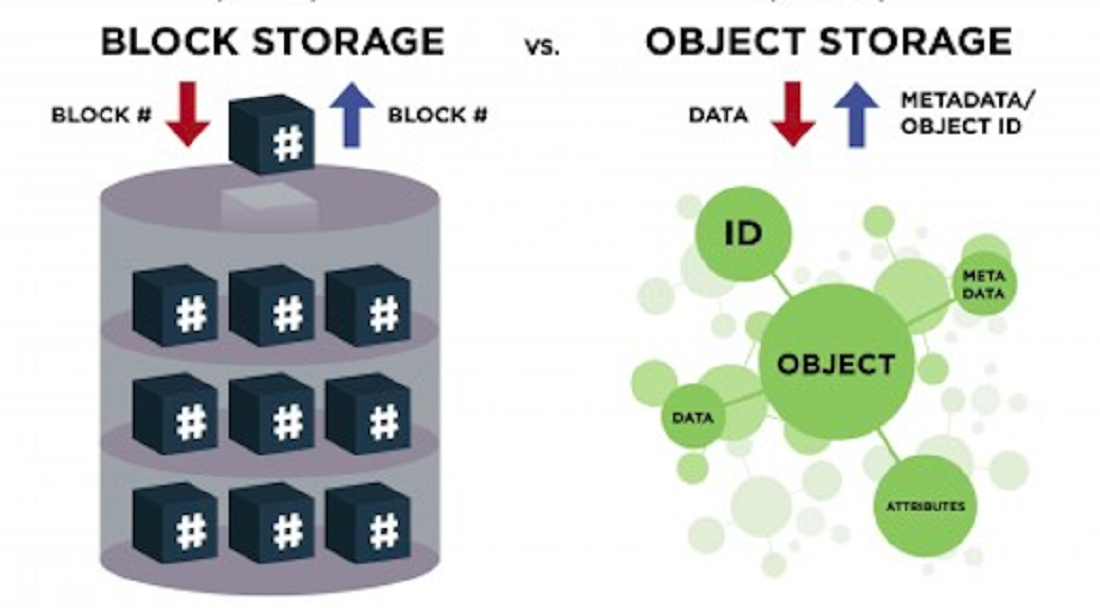 Параметры блокировки общего доступа S3 переопределяют другие разрешения доступа S3, что позволяет администратору учетной записи применять политику «запрета общего доступа» независимо от того, как добавляется объект, как создается сегмент или существуют ли существующие разрешения на доступ. Элементы управления S3 Block Public Access поддаются аудиту, обеспечивают дополнительный уровень контроля и используют проверки разрешений корзины AWS Trusted Advisor, журналы AWS CloudTrail и оповещения Amazon CloudWatch. Вы должны включить блокировку общего доступа для всех учетных записей и сегментов, которые вы не хотите открывать для всех.
Параметры блокировки общего доступа S3 переопределяют другие разрешения доступа S3, что позволяет администратору учетной записи применять политику «запрета общего доступа» независимо от того, как добавляется объект, как создается сегмент или существуют ли существующие разрешения на доступ. Элементы управления S3 Block Public Access поддаются аудиту, обеспечивают дополнительный уровень контроля и используют проверки разрешений корзины AWS Trusted Advisor, журналы AWS CloudTrail и оповещения Amazon CloudWatch. Вы должны включить блокировку общего доступа для всех учетных записей и сегментов, которые вы не хотите открывать для всех.
Владение объектами S3 — это функция, которая отключает списки управления доступом (ACL), передавая право собственности на все объекты владельцу корзины и упрощая управление доступом к данным, хранящимся в S3. При настройке параметра Владение объектами S3 Владелец корзины принудительно списки управления доступом больше не будут влиять на разрешения для вашей корзины и объектов в ней. Весь контроль доступа будет определяться с помощью политик на основе ресурсов, пользовательских политик или некоторой их комбинации.
Весь контроль доступа будет определяться с помощью политик на основе ресурсов, пользовательских политик или некоторой их комбинации.
Используя точки доступа S3, которые ограничены виртуальным частным облаком (VPC), вы можете легко защитить свои данные S3 в своей частной сети. Кроме того, вы можете использовать политики управления сервисами AWS, чтобы потребовать, чтобы любая новая точка доступа S3 в вашей организации была ограничена доступом только к VPC.
Анализатор доступа IAM для S3 — это функция, которая помогает упростить управление разрешениями при настройке, проверке и уточнении политик для корзин S3 и точек доступа. Анализатор доступа для S3 отслеживает существующие политики доступа к корзинам, чтобы убедиться, что они предоставляют только необходимый доступ к вашим ресурсам S3. Анализатор доступа для S3 оценивает ваши политики доступа к корзинам, чтобы вы могли быстро исправить любые корзины с доступом, который не требуется. При просмотре результатов, которые показывают потенциально общий доступ к корзине, вы можете заблокировать общий доступ к корзине одним щелчком мыши в консоли S3. В целях аудита вы можете загрузить результаты Access Analyzer для S3 в виде отчета в формате CSV. Кроме того, консоль S3 сообщает о предупреждениях безопасности, ошибках и предложениях от IAM Access Analyzer при создании политик S3. Консоль автоматически запускает более 100 проверок политик для проверки ваших политик. Эти проверки экономят ваше время, помогают устранять ошибки и применять передовые методы обеспечения безопасности.
В целях аудита вы можете загрузить результаты Access Analyzer для S3 в виде отчета в формате CSV. Кроме того, консоль S3 сообщает о предупреждениях безопасности, ошибках и предложениях от IAM Access Analyzer при создании политик S3. Консоль автоматически запускает более 100 проверок политик для проверки ваших политик. Эти проверки экономят ваше время, помогают устранять ошибки и применять передовые методы обеспечения безопасности.
IAM упрощает анализ доступа и уменьшает разрешения для достижения наименьших привилегий, предоставляя отметку времени, когда пользователь или роль в последний раз использовали S3 и связанные действия. Используйте эту информацию о последнем доступе для анализа доступа к S3, выявления неиспользуемых разрешений и их надежного удаления. Дополнительные сведения см. в разделе «Уточнение разрешений с использованием данных о последнем доступе».
Вы можете использовать Amazon Macie для обнаружения и защиты конфиденциальных данных, хранящихся в Amazon S3. Macie автоматически собирает полную инвентаризацию S3 и постоянно оценивает каждую корзину, чтобы предупредить о любых общедоступных корзинах, незашифрованных корзинах или корзинах, совместно используемых или реплицированных с учетными записями AWS за пределами вашей организации. Затем Macie применяет методы машинного обучения и сопоставления шаблонов к выбранным вами корзинам, чтобы идентифицировать и предупреждать вас о конфиденциальных данных, таких как личная информация (PII). По мере получения данных о безопасности они передаются в события Amazon CloudWatch, что упрощает интеграцию с существующими системами рабочих процессов и инициирование автоматического исправления с помощью таких сервисов, как AWS Step Functions, для выполнения таких действий, как закрытие общедоступной корзины или добавление тегов ресурсов.
Macie автоматически собирает полную инвентаризацию S3 и постоянно оценивает каждую корзину, чтобы предупредить о любых общедоступных корзинах, незашифрованных корзинах или корзинах, совместно используемых или реплицированных с учетными записями AWS за пределами вашей организации. Затем Macie применяет методы машинного обучения и сопоставления шаблонов к выбранным вами корзинам, чтобы идентифицировать и предупреждать вас о конфиденциальных данных, таких как личная информация (PII). По мере получения данных о безопасности они передаются в события Amazon CloudWatch, что упрощает интеграцию с существующими системами рабочих процессов и инициирование автоматического исправления с помощью таких сервисов, как AWS Step Functions, для выполнения таких действий, как закрытие общедоступной корзины или добавление тегов ресурсов.
AWS PrivateLink для S3 обеспечивает частное подключение между Amazon S3 и локальной средой. Вы можете предоставить интерфейсные конечные точки VPC для S3 в вашем VPC, чтобы напрямую подключать локальные приложения к S3 через AWS Direct Connect или AWS VPN. Запросы на интерфейс конечных точек VPC для S3 автоматически перенаправляются на S3 по сети Amazon. Вы можете установить группы безопасности и настроить политики конечных точек VPC для оконечных точек интерфейса VPC для дополнительных средств управления доступом.
Запросы на интерфейс конечных точек VPC для S3 автоматически перенаправляются на S3 по сети Amazon. Вы можете установить группы безопасности и настроить политики конечных точек VPC для оконечных точек интерфейса VPC для дополнительных средств управления доступом.
Обработка данных
S3 Object Lambda
С помощью S3 Object Lambda вы можете добавлять свой собственный код в запросы S3 GET, HEAD и LIST для изменения и обработки данных по мере их возврата в приложение. Вы можете использовать пользовательский код для изменения данных, возвращаемых стандартными запросами S3 GET, для фильтрации строк, динамического изменения размера изображений, редактирования конфиденциальных данных и многого другого. Вы также можете использовать S3 Object Lambda для изменения вывода запросов S3 LIST для создания пользовательского представления объектов в корзине и запросов S3 HEAD для изменения метаданных объекта, таких как имя и размер объекта. Благодаря функциям AWS Lambda ваш код работает в инфраструктуре, полностью управляемой AWS, что устраняет необходимость создавать и хранить производные копии ваших данных или запускать дорогостоящие прокси-серверы, и все это без каких-либо изменений в приложениях.
S3 Object Lambda использует функции AWS Lambda для автоматической обработки выходных данных стандартного запроса S3 GET, HEAD или LIST. AWS Lambda — это бессерверный сервис вычислений, который запускает определяемый пользователем код, не требуя управления базовыми вычислительными ресурсами. Всего несколькими щелчками мыши в Консоли управления AWS можно настроить функцию Lambda и подключить ее к точке доступа S3 Object Lambda. С этого момента S3 будет автоматически вызывать вашу функцию Lambda для обработки любых данных, полученных через S3 Object Lambda Access Point, возвращая преобразованный результат обратно в приложение. Вы можете создавать и выполнять собственные пользовательские функции Lambda, адаптируя преобразование данных S3 Object Lambda к вашему конкретному варианту использования.
Узнайте больше, посетив страницу функции S3 Object Lambda.
Запрос на месте
Amazon S3 имеет встроенную функцию и дополнительные сервисы, которые запрашивают данные без необходимости их копирования и загрузки в отдельную аналитическую платформу или хранилище данных. Это означает, что вы можете запускать аналитику больших данных непосредственно на своих данных, хранящихся в Amazon S3. S3 Select — это функция S3, предназначенная для повышения производительности запросов до 400 % и снижения затрат на запросы до 80 %. Он работает путем извлечения подмножества данных объекта (с использованием простых выражений SQL), а не всего объекта целиком, размер которого может достигать 5 терабайт.
Это означает, что вы можете запускать аналитику больших данных непосредственно на своих данных, хранящихся в Amazon S3. S3 Select — это функция S3, предназначенная для повышения производительности запросов до 400 % и снижения затрат на запросы до 80 %. Он работает путем извлечения подмножества данных объекта (с использованием простых выражений SQL), а не всего объекта целиком, размер которого может достигать 5 терабайт.
Amazon S3 также совместим с сервисами аналитики AWS Amazon Athena и Amazon Redshift Spectrum. Amazon Athena запрашивает ваши данные в Amazon S3 без необходимости их извлечения и загрузки в отдельный сервис или платформу. Он использует стандартные выражения SQL для анализа ваших данных, выдает результаты в течение нескольких секунд и обычно используется для обнаружения нерегламентированных данных. Amazon Redshift Spectrum также выполняет SQL-запросы непосредственно к хранящимся данным в Amazon S3 и больше подходит для сложных запросов и больших наборов данных (до эксабайт). Поскольку Amazon Athena и Amazon Redshift используют общий каталог данных и форматы данных, вы можете использовать их оба для одних и тех же наборов данных в Amazon S3.
Поскольку Amazon Athena и Amazon Redshift используют общий каталог данных и форматы данных, вы можете использовать их оба для одних и тех же наборов данных в Amazon S3.
Передача данных
AWS предлагает портфель услуг по передаче данных, чтобы обеспечить правильное решение для любого проекта миграции данных. Уровень подключения является основным фактором миграции данных, и у AWS есть предложения, которые могут удовлетворить потребности вашего гибридного облачного хранилища, онлайн-передачи данных и офлайн-передачи данных.
Гибридное облачное хранилище: AWS Storage Gateway — это сервис гибридного облачного хранилища, который позволяет легко подключать локальные приложения к AWS Storage и расширять их. Клиенты используют Storage Gateway для плавной замены ленточных библиотек облачным хранилищем, предоставления общих файловых ресурсов в облачном хранилище или создания кэша с малой задержкой для доступа к данным в AWS для локальных приложений.
Онлайн-передача данных: AWS DataSync позволяет легко и эффективно передавать сотни терабайт и миллионы файлов в Amazon S3, до 10 раз быстрее, чем инструменты с открытым исходным кодом.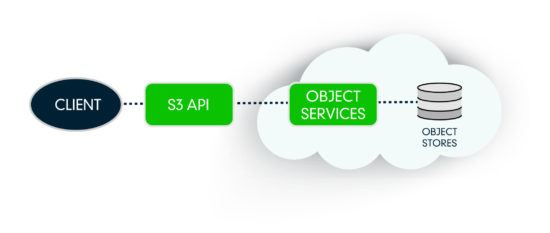 DataSync автоматически обрабатывает или устраняет многие ручные задачи, включая сценарии заданий копирования, планирование и мониторинг передачи, проверку данных и оптимизацию использования сети. Кроме того, вы можете использовать AWS DataSync для копирования объектов между корзиной на S3 в Outposts и корзиной, хранящейся в регионе AWS. AWS Transfer Family обеспечивает полностью управляемую, простую и бесперебойную передачу файлов в Amazon S3 с использованием SFTP, FTPS и FTP. Amazon S3 Transfer Acceleration обеспечивает быструю передачу файлов на большие расстояния между вашим клиентом и корзиной Amazon S3.
DataSync автоматически обрабатывает или устраняет многие ручные задачи, включая сценарии заданий копирования, планирование и мониторинг передачи, проверку данных и оптимизацию использования сети. Кроме того, вы можете использовать AWS DataSync для копирования объектов между корзиной на S3 в Outposts и корзиной, хранящейся в регионе AWS. AWS Transfer Family обеспечивает полностью управляемую, простую и бесперебойную передачу файлов в Amazon S3 с использованием SFTP, FTPS и FTP. Amazon S3 Transfer Acceleration обеспечивает быструю передачу файлов на большие расстояния между вашим клиентом и корзиной Amazon S3.
Автономная передача данных. Семейство AWS Snow специально создано для использования на периферии, где пропускная способность сети ограничена или отсутствует, и обеспечивает возможности хранения и вычислений в суровых условиях. В сервисе AWS Snowball для сбора, обработки и миграции данных используются портативные устройства хранения повышенной прочности и периферийные вычислительные устройства. Клиенты могут отправить физическое устройство Snowball для автономной миграции данных в AWS. AWS Snowmobile — это сервис передачи данных эксабайтного масштаба, используемый для перемещения огромных объемов данных в облако, включая видеобиблиотеки, репозитории изображений, или даже полной миграции центра обработки данных.
Клиенты могут отправить физическое устройство Snowball для автономной миграции данных в AWS. AWS Snowmobile — это сервис передачи данных эксабайтного масштаба, используемый для перемещения огромных объемов данных в облако, включая видеобиблиотеки, репозитории изображений, или даже полной миграции центра обработки данных.
Клиенты также могут работать со сторонними поставщиками из Партнерская сеть AWS (APN) для развертывания гибридных архитектур хранения, интеграции Amazon S3 в существующие приложения и рабочие процессы и передачи данных в облако AWS и из него.
Узнайте больше, посетив сервисы переноса облачных данных AWS » , AWS Storage Gateway » , AWS DataSync » , Семейство AWS Transfer » , Amazon S3 Transfer Acceleration » , Семейство AWS Snow »
Производительность
Amazon S3 обеспечивает лучшую в отрасли производительность для облака хранение объектов. Amazon S3 поддерживает параллельные запросы, что означает, что вы можете масштабировать производительность S3 в зависимости от вашего вычислительного кластера без каких-либо настроек вашего приложения. Производительность масштабируется для каждого префикса, поэтому вы можете использовать столько префиксов, сколько вам нужно параллельно для достижения требуемой пропускной способности. Количество префиксов не ограничено. Производительность Amazon S3 поддерживает не менее 3 500 запросов в секунду на добавление данных и 5 500 запросов в секунду на извлечение данных. Каждый префикс S3 может поддерживать эти скорости запросов, что упрощает значительное повышение производительности.
Производительность масштабируется для каждого префикса, поэтому вы можете использовать столько префиксов, сколько вам нужно параллельно для достижения требуемой пропускной способности. Количество префиксов не ограничено. Производительность Amazon S3 поддерживает не менее 3 500 запросов в секунду на добавление данных и 5 500 запросов в секунду на извлечение данных. Каждый префикс S3 может поддерживать эти скорости запросов, что упрощает значительное повышение производительности.
Для достижения этой скорости запросов S3 вам не нужно рандомизировать префиксы объектов для повышения производительности. Это означает, что вы можете использовать логические или последовательные шаблоны именования в именовании объектов S3 без каких-либо последствий для производительности. Актуальную информацию об оптимизации производительности для Amazon S3 см. в Руководстве по производительности для Amazon S3 и Шаблонах проектирования производительности для Amazon S3.
Согласованность
Amazon S3 обеспечивает строгую согласованность чтения и записи автоматически для всех приложений без изменений производительности или доступности, без ущерба для региональной изоляции приложений и без дополнительных затрат.
Похожие записи
-

 775 motor: Как работают двигатели постоянного тока 775
775 motor: Как работают двигатели постоянного тока 775 - Зубная щетка oral b замена аккумулятора: Как заменить аккумулятор Oral-B Type 3761, 3762, 3764 (Braun
- Штатная магнитола для пежо 408: Магнитолы Пежо 408 | штатные магнитолы пежо 408 андроид
- Диоды для лампы: Светоизлучающие диоды, или LED, – характеристики и преимущества